P03-08
Predicting Chemical Roles Using Natural Language Processing on Database Descriptions
Yuya KOIDE *1, Yuto MATSUMOTO2, Hiroaki GOTOH2
1College of Engineering Science, Yokohama National University
2Graduate School of Engineering, Yokohama National University
( * E-mail: koide-yuya-mc@ynu.jp )
With the development of natural language processing technology, it is possible to efficiently utilize the enormous amount of document data that experimental data and other data aggregate, and to predict the properties of compounds directly from the document data.
We clustered the embedded representations of compounds obtained by analyzing 1744 papers with the Word2Vec model and confirmed the structural features in each cluster. Furthermore, we identified the distribution of chemical descriptors in each cluster.
In this study, we further developed this previous study and introduced an approach to predict the presence or absence of various chemical roles of compounds by analyzing the descriptive text of compounds using natural language processing, focusing on databases containing aggregated article information.
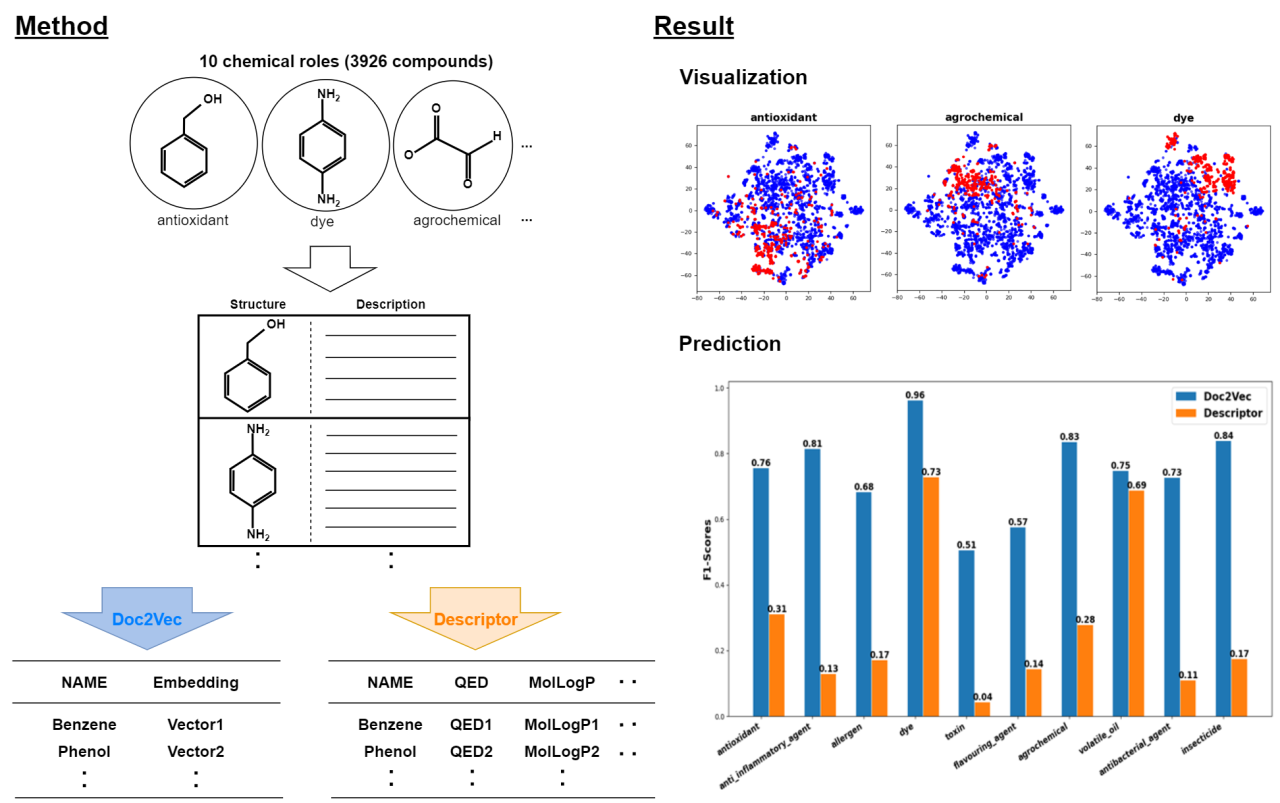
In this study, from a total of 41891 compounds registered as 3stars in ChEBI, a database of chemical compounds, 10 chemical roles (antioxidant, anti-inflammatory agent, allergen, dye, toxin, flavoring agent, agrochemical, volatile oil, antibacterial agent, insecticide) were extracted to a dataset of 3926 compounds. Then, embeddings of the compounds were obtained by natural language processing of the descriptions of those compounds obtained from PubChemAPI using the Doc2Vec model. Then, the presence or absence of each chemical role of the compounds was predicted by logistic regression using the obtained embeddings as input, and these results were compared with the F1 scores predicted from the 32 chemical descriptors. These 32 chemical descriptors were obtained from 208 chemical descriptors obtained by RDKit, extracting only those that were continuous values and those with a correlation coefficient of 0.95 or less between each descriptor.
The obtained embeddings of the compounds were found to be distributed for each chemical role. Furthermore, the prediction of the presence or absence of each chemical role by the embeddings was better than that by the chemical descriptors for many tasks. On the other hand, the prediction accuracy of dyes and volatile oils by this method was comparable to that by chemical descriptors, suggesting that compounds belonging to dyes and volatile oils may have similar structural characteristics. In addition, the prediction accuracy of toxin was low both by this method and by chemical descriptors, suggesting that compounds belonging to toxin include compounds with diverse structures and characteristics. Based on these results, we are considering what kind of substructure influences the presence or absence of each chemical role.
By analyzing the explanatory text of a group of compounds using Doc2Vec, it is possible to comprehensively analyze and understand the compounds, including their characteristics and behaviors that cannot be captured by their structures and physical properties. The embeddings obtained from the analysis can also be used as new descriptors that utilize the properties of the compounds.